How to Paginate an API

When building an API, it is important to consider how to handle large datasets. API Pagination is a common way to break up large datasets into smaller chunks, or "pages", allowing the API to return a manageable amount of data per request. Large companies such as Twitter, Slack or Github use this type of strategy to scale their applications while maintaining a very good performance.
Why paginate an API?
Paginating an API is an essential practice for a number of reasons that are closely related.
Firstly, it can significantly enhance the performance of your application by decreasing the amount of data that needs to be loaded at any given time. This can avoid any delays or timeouts. Besides, it enables your application to be scalable, as it can manage a higher volume of requests without slowing down or crashing by restricting the amount of data that is returned in each request.
Moreover, pagination can enhance the user experience by decreasing loading time by fetching less data. It also reduces visual clutter on the page and provides greater flexibility by enabling users to choose the number of results they want to see on each page. This gives them more control over how they access and analyze information and reduces the number of results displayed.
Strategies for Pagination
The two most common strategies for paginating an API are offset pagination and cursor-based pagination. Offset pagination is the most straightforward approach, involving keeping track of a page number and the number of results per page. Cursor-based pagination is more complex, but it allows for more efficient requests by returning only the results that have changed since the last request. Let's go deeper…
Offset Pagination
As mentioned above, offset pagination is the easiest. An API that implements this pattern needs two parameters: offset and limit. The "offset" is the number of elements that have been "skipped" to get to the current page, and "limit" is the number of elements per page. This strategy can be implemented in a number of ways, but a common way is through query parameters such as offset and limit. Both can be used interchangeably.
Suppose that each square is an element and the number its id.

One of the best benefits of this type of pagination is that you can jump to any page immediately. For example, you can skip 600 records and take 15, which is like going directly to page 41 of the result set. Also, we can sort the elements based on other attributes such as alphabetical order by first and last name, and we will have no problems.
Now, suppose we have 21 records and we paginate every 8 elements, that is, with a limit of 8. And, the first page has the most recent elements and the last page has the oldest ones. The following image shows how the records are divided into pages.

While we are on the first page, the data is updated by three new records.
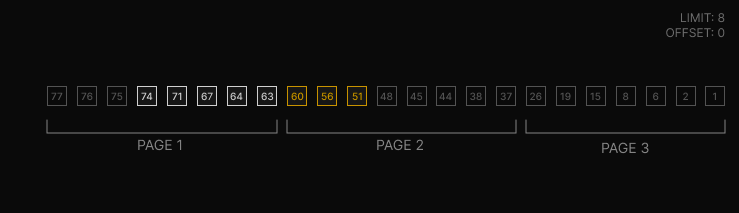
Now we navigate to the second page. As you can see in the image above, the behavior is not as expected, since the last records on page 1 will appear on page 2.
So this is an important consideration when choosing this type of pagination. When using real-time data or adding records at every instant, offset pagination can be a problem because the data we get will not be consistent from one page to another, as it will be repeated. For example, infinite scrolling may cause you to have repeated elements.
The solution to this problem is cursor-based pagination.
Cursor-based Pagination
This strategy maintains a "limit" parameter but replaces the "offset" parameter with a "cursor". And the API returns a limited set of results before or after a given cursor**.** Generally the next or previous records are returned, but do not include the cursor record even if you can bring it to the cursor. This is an implementation issue and a preference of mine, but you can choose what you need.
An important consideration is that the cursor must be based on a unique, sequential column in the database. In this case, our cursor is the id but you can use timestamp.
The following image shows an example that returns 4 records after the record with id equal to 6, since it is the cursor.

As mentioned above, the benefit of this strategy is that the next page will always be consistent, in other words, it will never repeat records. But as a downside, we lose the possibility to jump to a specific page, because it is impossible to know or calculate the cursor, we can only go forward or backward.
Another important advantage of this strategy is the performance with large volumes of data. Cursor-based pagination is much more efficient than offset pagination, in the former the response time remains constant as the data grows, while in the latter the response time increases linearly. This will be demonstrated in the implementation.
But, sorting elements based on other attributes with this type of strategy can be a problem. While it can be done, we will lose the performance advantage.
Implementation
For the practical methods I will make a small implementation with node.js of both strategies.The example is an api that simulates twitter. It is quite simple, it just returns tweets. The database contains 2,400,000 records and the tweets have the following interface.
interface Tweet {
id: string
createdAt: string
content: string
author: string
likes: number
}The API has only 2 endpoints that implement each strategy
const app = new App();
app.get("/offset", offsetHandler)
.get("/cursor", cursorHandler)
.listen(3000);
async function offsetHandler(req: Request, res: Response) {
const offset = Number(req.query.offset);
const limit = Number(req.query.limit);
const paginatedTweets = await knex("Tweet")
.offset(offset)
.limit(limit)
.orderBy("id", "asc")
.select();
res.json(paginatedTweets);
}
export { offsetHandler };async function cursorHandler(req: Request, res: Response) {
const cursor = String(req.query.cursor);
const limit = Number(req.query.limit);
let paginatedTweets: Tweet[] = [];
// This condition is required to return to the previous page when limit is negative
if (limit < 0) {
// Query returns paginated tweets before cursor
paginatedTweets = await knex
.fromRaw(
'(SELECT * FROM "Tweet" AS T WHERE T.id < ? ORDER BY T.id DESC)',
cursor
)
.limit(Math.abs(limit))
.select();
return res.json(paginatedTweets.reverse());
}
paginatedTweets = await knex("Tweet")
.where("id", Number(limit) < 0 ? "<" : ">", cursor)
.limit(limit)
.orderBy("id", Number(limit) < 0 ? "desc" : "asc")
.select();
res.json(paginatedTweets);
}Finally, we can test the API with curl.
curl "localhost:3000/offset?offset=100&limit=10"
curl "localhost:3000/cursor?cursor=f55595cd-d0db-4761-8508-18a88d596324&limit=10"Performing a small benchmark of 1000 requests on records that are near the end of the table I obtained the following.
| Metric | Offset | Cursor |
|---|---|---|
| Median | 96 ms | 1 ms |
| Average | 97.36 ms | 1.19 ms |
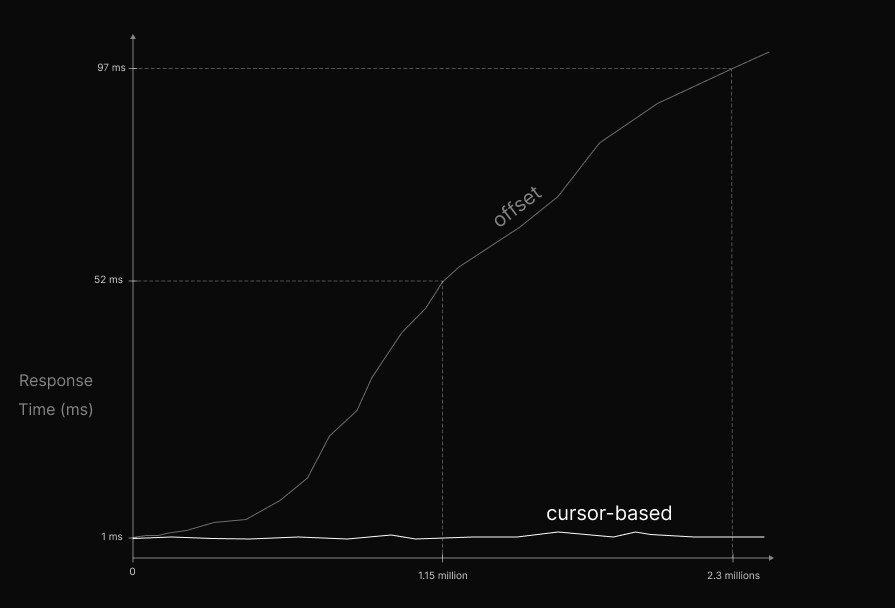
With "cursor-based" half of the requests are executed in 1 ms or less, while with "offset" half take 96 ms or less. In addition, cursor-based is 82 times faster on average.
However, it is important to note that these data only apply to the specific events that were measured and cannot be generalized to all situations. Results may vary depending on the type of request, data size, hardware capacity, etc. But it is enough to prove that “cursor-based” is faster.
The image below shows in a generalized way how the response time grows as there is more data.
If you want to see the code in more detail and test it, you can find it in this repository.
Conclusion
Pagination is an important consideration when building an API, as it helps manage large datasets and provides a more efficient way for users to access the data. There are two strategies for paginating an API (of course there are many, many variations on these), and the best one to use will depend on several factors such as the size of the dataset, the rate at which data changes, and many more. Some aspects to consider when choosing one or the other:
Offset Pagination
Pros:
- Easy to implement
- Natively supported in most databases.
- Ability to jump to a specific page within the set.
Const:
- Can be less performant as the data set grows larger (doesn’t scale).
- Less performant for large data sets.
- Inconsistent results if data is added, removed or modified at a high frequency.
Cursor-based Pagination
Pros:
- More performant for large data sets.
- Allows for consistent results between pagination requests.
- Able to handle insertions and deletions of data while preserving pagination state.
Const:
- Requires a unique sequential column.
- Can’t jump to a specific page.
- More difficult to implement, as it is not natively supported in some databases.